



DeepSeek V3 Essentially the most Powerful Open-Source Language Model
페이지 정보

본문
 Last month, DeepSeek turned the AI world on its head with the release of a brand new, competitive simulated reasoning mannequin that was Free DeepSeek Chat to download and use underneath an MIT license. That kind of coaching code is important to fulfill the Open Source Institute's formal definition of "Open Source AI," which was finalized last yr after years of study. Governments and companies should stability AI’s potential with essential laws and human oversight. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the hassle to ensure load stability. Firstly, DeepSeek-V3 pioneers an auxiliary-loss-free technique (Wang et al., 2024a) for load balancing, with the aim of minimizing the opposed influence on model performance that arises from the trouble to encourage load balancing. Finally, we meticulously optimize the reminiscence footprint during training, thereby enabling us to practice DeepSeek-V3 with out utilizing costly Tensor Parallelism (TP). Through the support for FP8 computation and storage, we obtain both accelerated coaching and decreased GPU memory usage. • At an economical cost of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the presently strongest open-source base model.
Last month, DeepSeek turned the AI world on its head with the release of a brand new, competitive simulated reasoning mannequin that was Free DeepSeek Chat to download and use underneath an MIT license. That kind of coaching code is important to fulfill the Open Source Institute's formal definition of "Open Source AI," which was finalized last yr after years of study. Governments and companies should stability AI’s potential with essential laws and human oversight. Compared with DeepSeek-V2, an exception is that we moreover introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the hassle to ensure load stability. Firstly, DeepSeek-V3 pioneers an auxiliary-loss-free technique (Wang et al., 2024a) for load balancing, with the aim of minimizing the opposed influence on model performance that arises from the trouble to encourage load balancing. Finally, we meticulously optimize the reminiscence footprint during training, thereby enabling us to practice DeepSeek-V3 with out utilizing costly Tensor Parallelism (TP). Through the support for FP8 computation and storage, we obtain both accelerated coaching and decreased GPU memory usage. • At an economical cost of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the presently strongest open-source base model.
 To achieve load balancing among totally different specialists within the MoE half, we want to make sure that each GPU processes roughly the same number of tokens. If merely having a different billing and delivery tackle have been evidence of sanctions-busting or smuggling, then pretty much every enterprise buy would qualify, and one may do the identical by setting their billing tackle any anyplace (e.g. CONUS) and delivery elsewhere. It allows you to look the web utilizing the same sort of conversational prompts that you normally interact a chatbot with. Quirks embrace being approach too verbose in its reasoning explanations and utilizing a number of Chinese language sources when it searches the web. "The DeepSeek model rollout is leading investors to query the lead that US corporations have and the way a lot is being spent and whether or not that spending will result in profits (or overspending)," stated Keith Lerner, analyst at Truist. Low-precision coaching has emerged as a promising resolution for environment friendly coaching (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being carefully tied to advancements in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). In this work, we introduce an FP8 mixed precision training framework and, for the primary time, validate its effectiveness on an extremely giant-scale model.
To achieve load balancing among totally different specialists within the MoE half, we want to make sure that each GPU processes roughly the same number of tokens. If merely having a different billing and delivery tackle have been evidence of sanctions-busting or smuggling, then pretty much every enterprise buy would qualify, and one may do the identical by setting their billing tackle any anyplace (e.g. CONUS) and delivery elsewhere. It allows you to look the web utilizing the same sort of conversational prompts that you normally interact a chatbot with. Quirks embrace being approach too verbose in its reasoning explanations and utilizing a number of Chinese language sources when it searches the web. "The DeepSeek model rollout is leading investors to query the lead that US corporations have and the way a lot is being spent and whether or not that spending will result in profits (or overspending)," stated Keith Lerner, analyst at Truist. Low-precision coaching has emerged as a promising resolution for environment friendly coaching (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being carefully tied to advancements in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). In this work, we introduce an FP8 mixed precision training framework and, for the primary time, validate its effectiveness on an extremely giant-scale model.
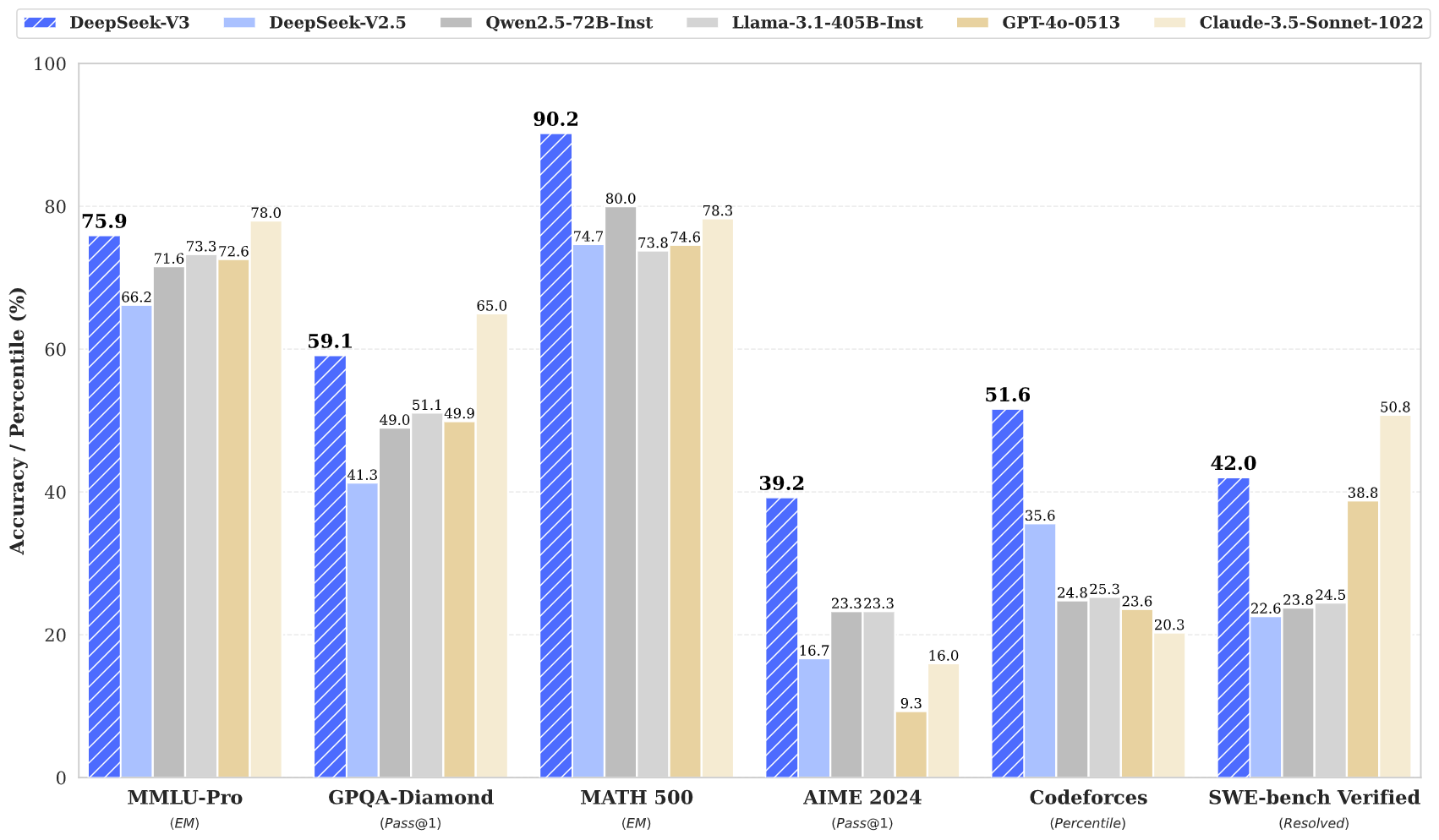
Among these fashions, DeepSeek has emerged as a strong competitor, providing a balance of efficiency, pace, and cost-effectiveness. Despite its economical training prices, comprehensive evaluations reveal that DeepSeek-V3-Base has emerged as the strongest open-supply base model at the moment accessible, particularly in code and math. However, its supply code and any specifics about its underlying information are not available to the general public. From this, we can see that both models are quite robust in reasoning capabilities, as they both supplied appropriate answers to all my reasoning questions. Through the submit-coaching stage, we distill the reasoning capability from the DeepSeek online-R1 sequence of models, and in the meantime fastidiously maintain the balance between mannequin accuracy and generation length. Identify efficient visitors era tools. The developments in DeepSeek online-V2.5 underscore its progress in optimizing model efficiency and effectiveness, solidifying its position as a leading participant within the AI landscape. 2) On coding-associated duties, DeepSeek-V3 emerges as the highest-performing mannequin for coding competitors benchmarks, corresponding to LiveCodeBench, solidifying its position as the main model in this domain. • Knowledge: (1) On academic benchmarks equivalent to MMLU, MMLU-Pro, and GPQA, DeepSeek-V3 outperforms all different open-supply models, attaining 88.5 on MMLU, 75.9 on MMLU-Pro, and 59.1 on GPQA. • We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 coaching on an extremely large-scale mannequin.
• Code, Math, and Reasoning: (1) DeepSeek-V3 achieves state-of-the-artwork efficiency on math-associated benchmarks among all non-lengthy-CoT open-supply and closed-supply fashions. Slightly totally different from DeepSeek-V2, DeepSeek-V3 makes use of the sigmoid function to compute the affinity scores, and applies a normalization among all chosen affinity scores to produce the gating values. POSTSUPERSCRIPT is the matrix to provide the decoupled queries that carry RoPE. Let Deep Seek coder handle your code needs and DeepSeek chatbot streamline your on a regular basis queries. It's presently unclear whether or not DeepSeek's planned open source release may also embody the code the crew used when coaching the model. Now, the company is preparing to make the underlying code behind that model more accessible, promising to release 5 open source repos starting next week. More detailed data on safety considerations is expected to be launched in the coming days. The open supply launch could additionally assist present wider and simpler access to DeepSeek whilst its cellular app is facing worldwide restrictions over privateness concerns. We offer complete documentation and examples that will help you get began.
If you have any thoughts about exactly where and how to use DeepSeek v3, you can speak to us at our internet site.
- 이전글It's Enough! 15 Things About Language Certificate Germany We're Sick Of Hearing 25.02.24
- 다음글10 Facts About Buy A Goethe Certificate That Make You Feel Instantly A Good Mood 25.02.24
댓글목록
등록된 댓글이 없습니다.














